SubQ Model Emerges
The AI model SubQ has made a groundbreaking entrance, claiming to redefine the landscape of AI models. It is the first model based on a fully sub-quadratic sparse attention architecture (SSA) with a context size of up to 12 million tokens.

SubQ’s core advantage lies in its SSA architecture, which dynamically selects focus points based on content, avoiding unnecessary calculations of all token relationships. Compared to traditional Transformers, SubQ reduces computation by a factor of 1000.
Experimental results show that with a context of 1 million tokens, SubQ is 52 times faster than FlashAttention, costing less than 5% of Claude Opus.

The company behind this architecture, Subquadratic, is based in Miami and consists of just 13 employees. AI expert Bindu Reddy remarked, “If this is true, the valuations of Anthropic and OpenAI would drop to zero!”
Others believe this is the true way to scale LLMs moving forward.

The Original Sin of Transformers
In 2017, Google’s paper “Attention is All You Need” established the dominance of the Transformer architecture. For the past nine years, all leading models, from GPT to Claude to Gemini, have been built on the same foundation: dense attention mechanisms.

Transformers operate by comparing each token with all other tokens in the sequence, leading to a quadratic complexity. As the context doubles, computation costs quadruple, making longer inputs more expensive, slower, and prone to failure.
This explains why most LLMs are capped at around 1 million tokens; it’s not that technology can’t handle longer inputs, but that they become too costly to process.
The emergence of SubQ fundamentally changes this equation.

The Birth of SSA Architecture
The core breakthrough of SubQ is SSA—Subquadratic Sparse Attention. Its approach is surprisingly simple: it avoids comparing every token with all others. Since most attention weights in a trained model are close to zero, why calculate them?
SSA selects the truly relevant positions in the sequence based on content for each query, calculating attention only at these points and skipping over 99% of unnecessary computations.
Key Features of SSA
- Linear Scaling: Computation grows with the number of selected positions, not the entire sequence length. Doubling the context only doubles the cost, rather than quadrupling it.
- Content-Dependent Routing: The model determines where to look based on semantics, not position. Key information can be found whether it’s the 3rd token or the 1,100,000th token in the sequence.
- Precise Retrieval: Unlike recurrent models that compress information into a fixed state, SSA retains the ability to retrieve information accurately from any position.
In essence, SSA does not make dense attention faster; it reduces the amount of attention computation the model performs.

Reduced computation directly translates to speed.
Speed and Cost Advantages
SubQ’s released data is striking:
At 1 million tokens, SSA is 52.2 times faster than standard dense attention with FlashAttention-2.

At 128,000 tokens, it’s 7.2 times faster; at 256,000 tokens, 13.2 times; and at 512,000 tokens, 23 times faster. The longer the context, the more pronounced the advantage.
This reflects the linear scaling of SSA—dense attention becomes slower with longer inputs, while SSA becomes more cost-effective.

Regarding computational consumption, at 1 million tokens, attention FLOP is reduced by 62.5 times, and at 12 million tokens, this number approaches 1000 times.

In terms of cost, Subquadratic provides a clear comparison:
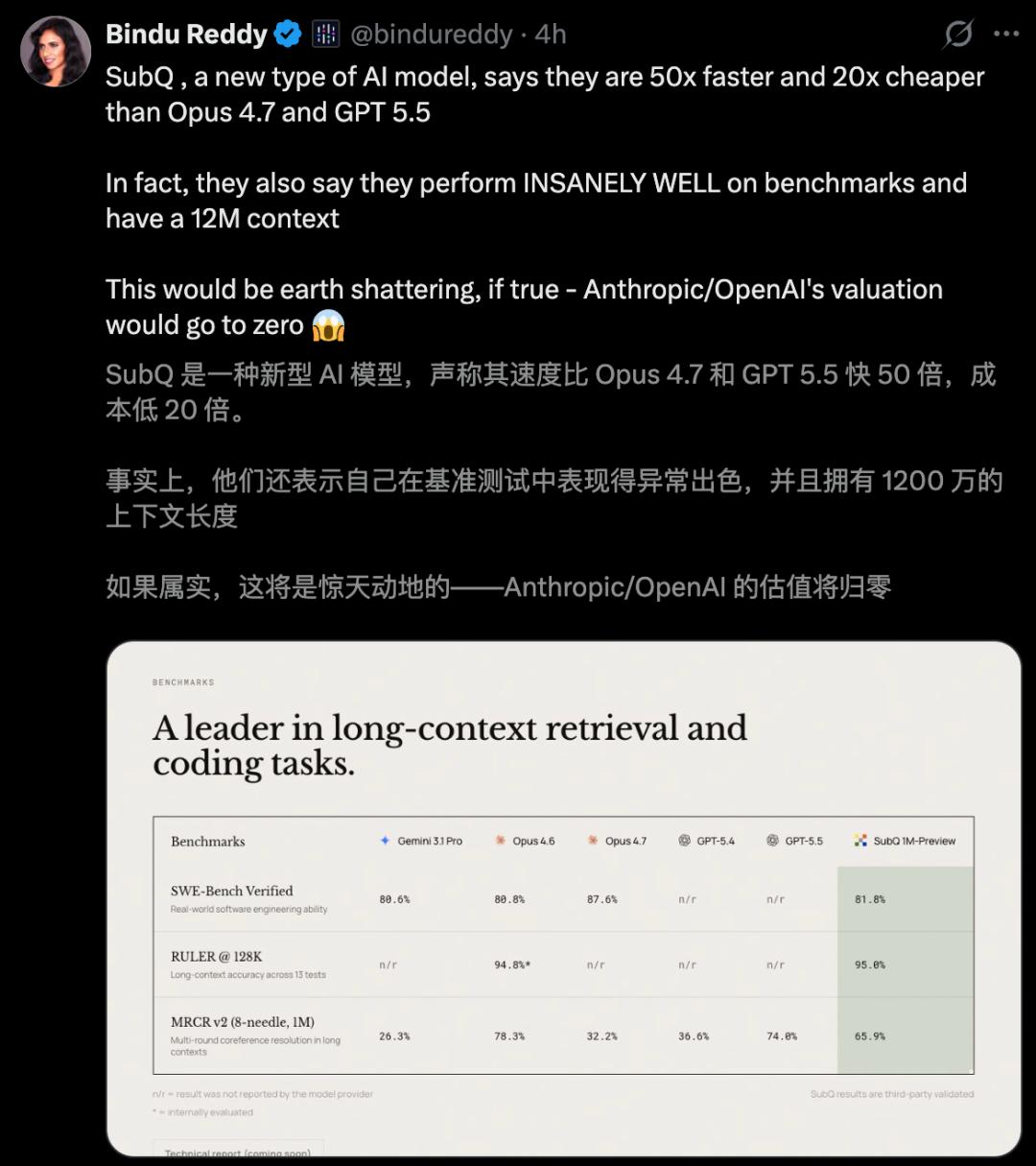
In the RULER 128K benchmark test, SubQ costs $8, while Opus costs $2600, resulting in a staggering 300 times cost difference.
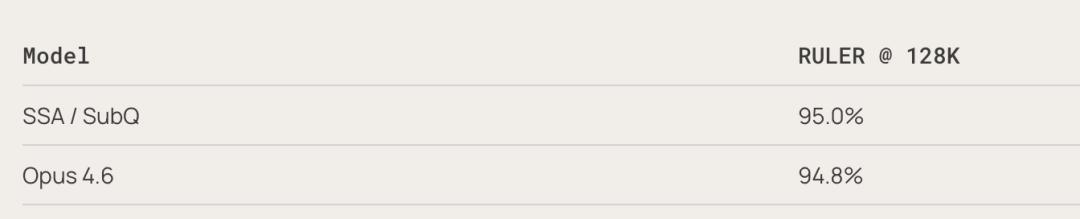
Importantly, these speed and cost advantages do not come at the expense of accuracy. In the RULER 128K benchmark test, SubQ achieved 95% accuracy, while Opus 4.6 was at 94.8%.
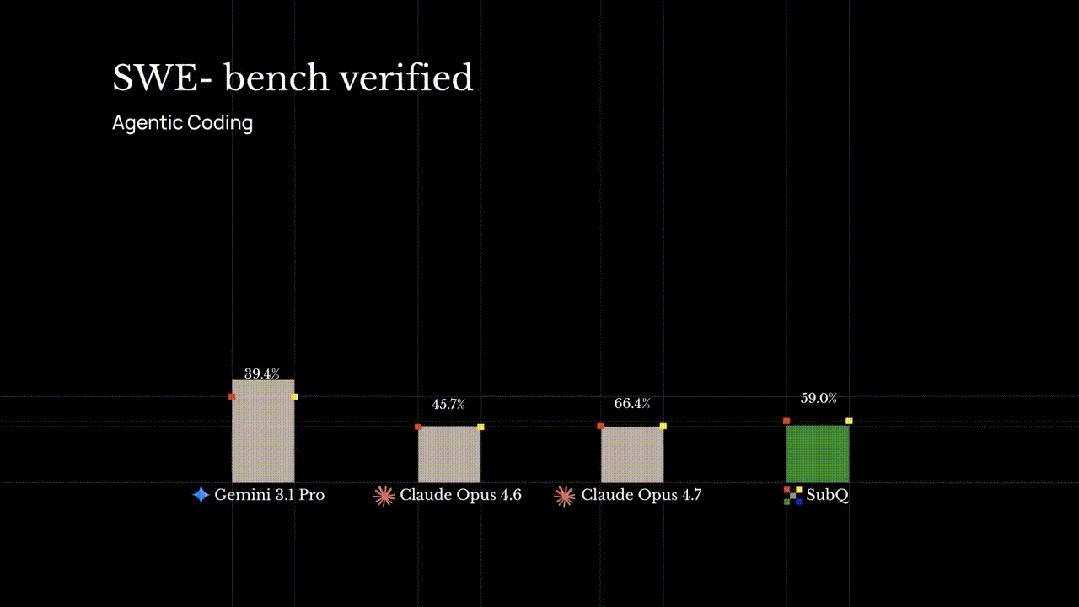
In SWE-Bench Verified (code engineering), SubQ scored 81.8, surpassing Opus 4.6’s 80.8. In MRCR v2 (long context retrieval), SubQ scored 65.9%, although lower than Opus 4.6’s 78%, it far exceeded GPT 5.4 (39%) and Gemini 3.1 Pro (23%).
These numbers are alarming— a seed-stage company, using less than 5% of Opus’s cost, is matching or exceeding the flagship models of Anthropic and OpenAI in several core benchmark tests.

With a single prompt, SubQ can handle 12 million tokens of extensive information, whether it’s an entire codebase, months of PR records, or the state of a long-running AI agent, all at a cost of just one-fifth of the original.

If all this proves true, it would represent the most significant architectural breakthrough since the advent of Transformers.
A 13-Person Startup Aiming to Disrupt Transformers
Founded in 2024, Subquadratic raised $29 million in seed funding, with a valuation of $500 million. It has two co-founders: CEO Justin Dangel and CTO Alexander Whedon.

The research team consists of 11 PhDs from Meta, Google, Oxford, Cambridge, and Adobe. Notably, the company was previously named Aldea, focusing on speech models before pivoting to attention architecture research.
Their product line includes:
- SubQ API: Full context interface for 12M tokens
- SubQ Code: Command-line coding agent, capable of processing an entire codebase at once
- SubQ Search: Deep research tool, initially free
Community Reactions: Terminator or AI Version of Theranos?
Within hours of SubQ’s release, the AI community split into two camps. AI expert Dan McAteer summed up the sentiment: SubQ is either the biggest breakthrough since Transformers or the AI equivalent of Theranos.

Supporters are numerous, with some claiming this is one of the most insane AI releases of 2026. Subquadratic may have found a significant breakthrough in architecture.

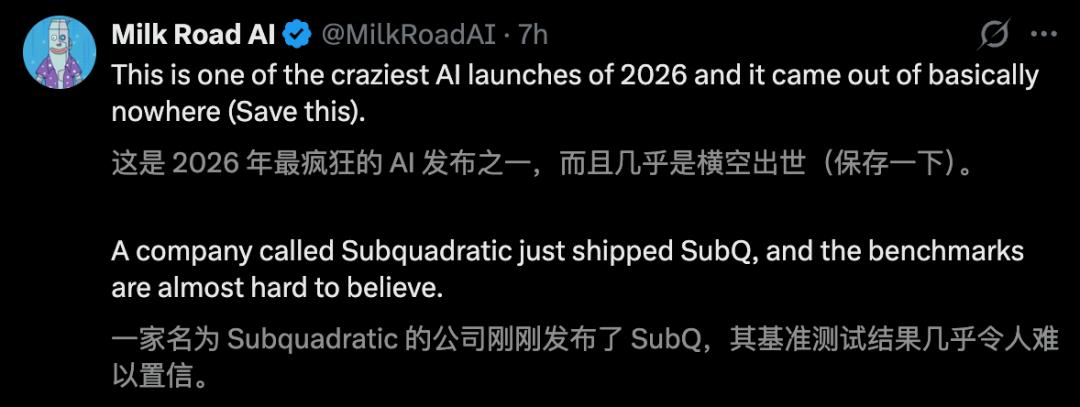
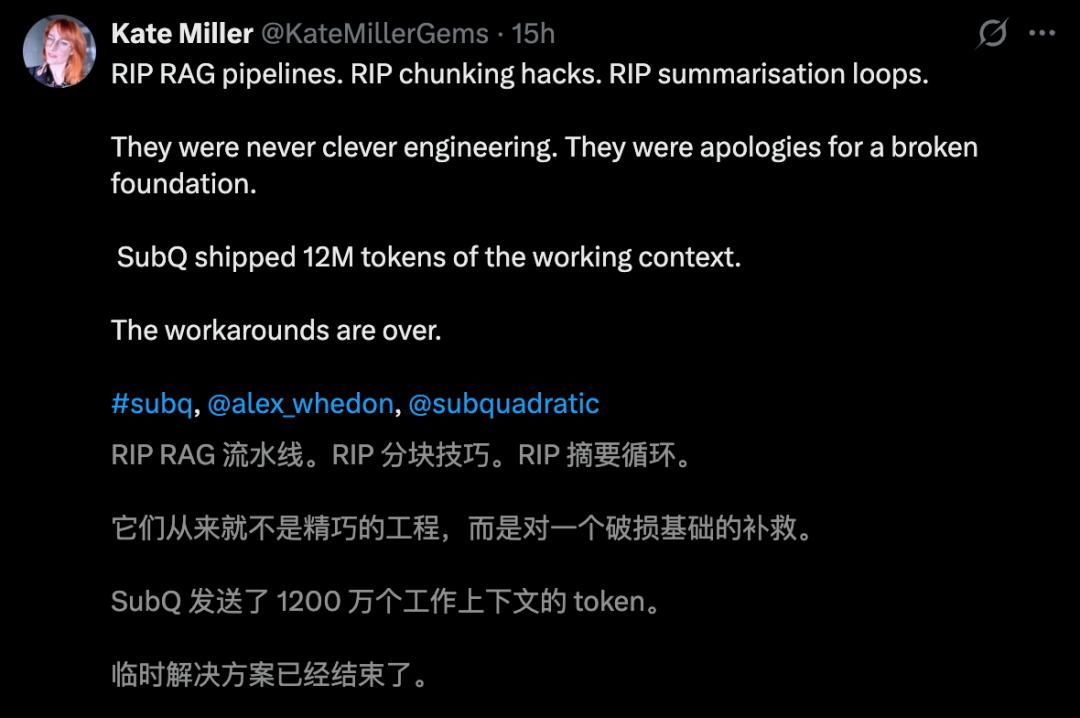
However, skeptics are equally vocal, with some labeling it a “scam company,” especially after reviewing the founders’ LinkedIn profiles.

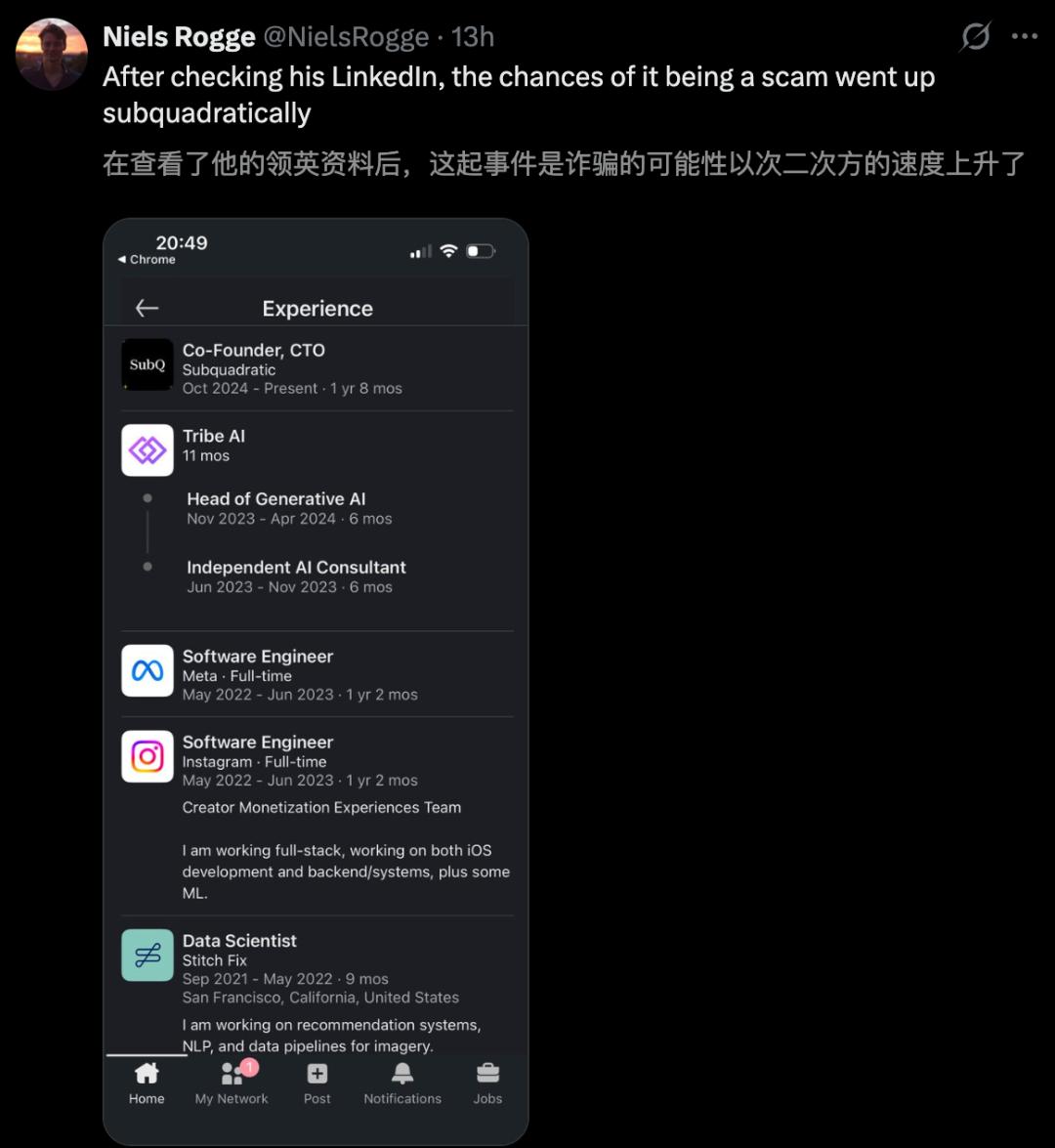
Former OpenAI researcher Will Depue pointed out that “SubQ is almost certainly based on Kimi or DeepSeek’s sparse attention fine-tuning.”
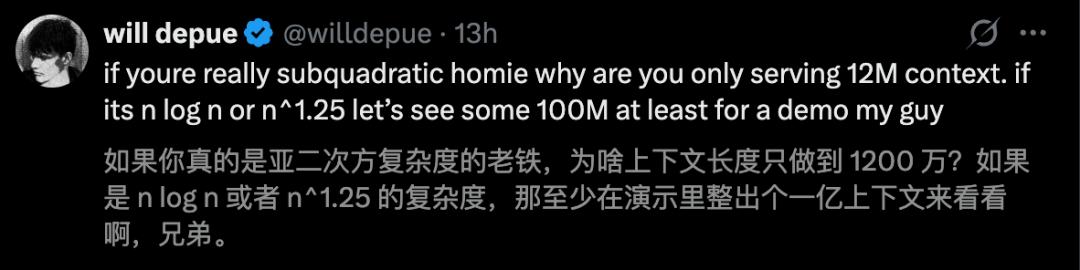

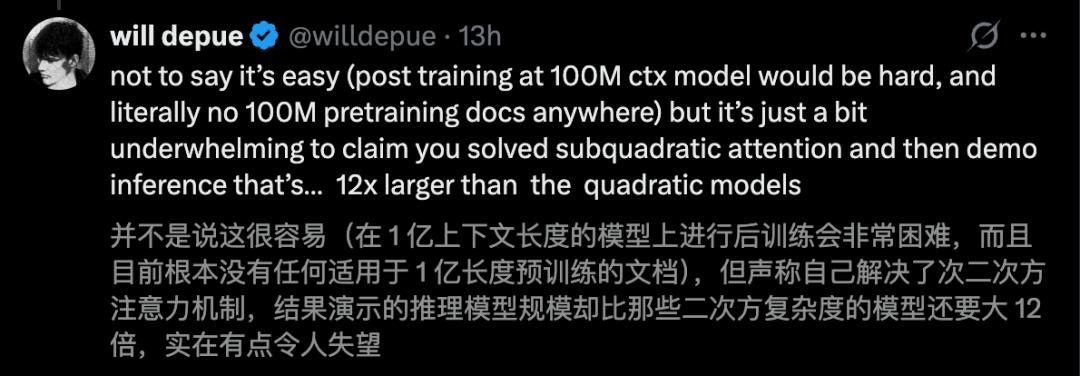
The AI community has seen too many stories of “peak at release”; the gap between presentation slides and real-world deployment is vast. However, because the stakes are high, the industry cannot afford to ignore this.
The true answer may only be revealed once technical reports are published and independent benchmarks are replicated.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.